What Is a Multimodal Approach in AI? A Complete Overview for Businesses and Innovators
Why Multimodal AI Matters Today
Artificial Intelligence has evolved from analyzing single data types (like only text) to understanding images, speech, video, documents, and sensor data together. This transformational upgrade is powered by the multimodal approach in AI - a key innovation driving more human-like intelligence, better automation, and advanced AI development services across industries.
Businesses today produce huge volumes of mixed data such as:
- Product images
- Customer conversations and voice recordings
- Video feeds
- IoT and sensor data
- Financial and operational documents
Traditional unimodal AI models struggle because they learn from only one data source. This limits accuracy and real-world decision-making.
Multimodal AI solves this by merging multiple data sources to generate context-aware intelligence.
Enterprises adopting multimodal models gain advantages in predictive analytics, automation, personalization, and innovative product development - making it a priority for modernsoftware developmentand digital transformation.
What Is a Multimodal Approach in AI?
A multimodal approach in Artificial Intelligence enables models to understand, process, and generate output from multiple data modalities - including text, visual information, audio, and structured data - at the same time.
Simple Definition
Multimodal AI = Multi-data understanding + Unified intelligence
Example:
You upload a product image and describe its features → AI analyzes both to provide recommendations or classifications more accurately.
This enables:
- Better reasoning
- Richer context
- More accurate predictions
- Human-like responses
Multimodal intelligence is becoming a core component of future AI software development and AI integration solutions.
How Does Multimodal AI Work?
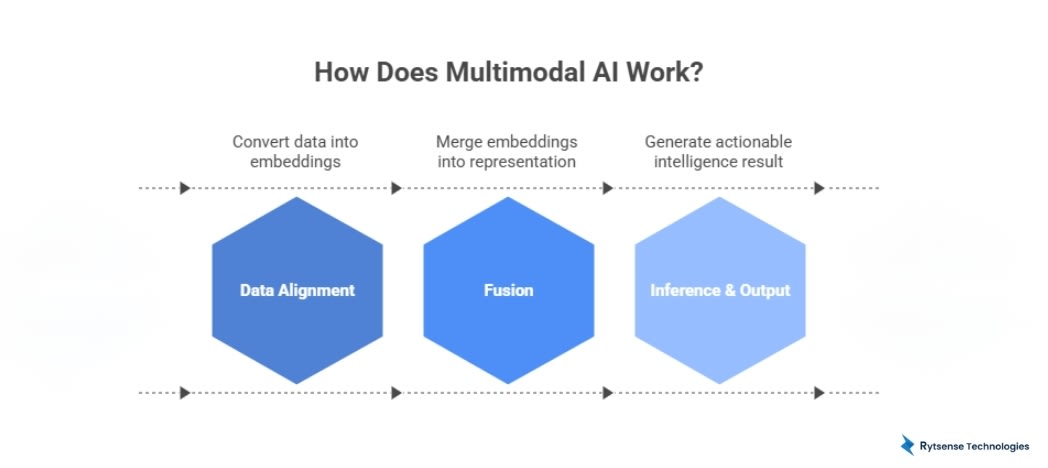
Multimodal AI works by enabling artificial intelligence models to understand and combine multiple types of data - such as text, audio, images, video, and sensor signals - all at once. To achieve this, multimodal systems follow a three-stage machine learning pipeline that turns diverse inputs into unified, actionable intelligence.
Multimodal systems follow a unified learning flow:
StageFunctionPurposeData AlignmentConvert different data types into embeddingsMakes all inputs machine-readableFusionMerge embeddings into unified representationAllows cross-modal understandingInference & OutputAI generates result (label, answer, recommendation)Actionable intelligence
Real-World Scenario: How Multimodal AI Powers Self-Driving Vehicles
The line:
Self-driving vehicles combine camera vision , radar, GPS, LiDAR → safer decisions. This architecture supports scalableAI application development for enterprises.
sounds simple, but under the hood it represents a full multimodal AI pipeline very similar to what enterprises can use for other domains like finance, healthcare, or manufacturing.
Let’s break it down step by step.
The Different Modalities in a Self-Driving Car
A self-driving vehicle uses multiple sensors, each providing a different “view” of the world:
Camera Vision
Captures 2D images and video.
Recognizes:
Lane markingsTraffic lights (red/yellow/green)Road signs (stop, speed limit, turn)Pedestrians, cars, bicycles, obstacles
Essentially gives the car “eyes”.
Radar
Uses radio waves to detect the distance and speed of objects.
Works well in poor weather (rain, fog, dust) where cameras may struggle.
Helps with:
Tracking moving vehicles
Estimating relative speed
Avoiding collisions
GPS (Global Positioning System)
Provides location on the map (latitude/longitude) plus sometimes speed.
Used for:
Navigation and route planning
Knowing which road or lane the vehicle should be on
Following a predefined path
LiDAR (Light Detection and Ranging)
Uses lasers to create a 3D point cloud of the surroundings.
Detects:
Distances to objects
Shapes and structure of the environment
Gives very precise 3D awareness (curbs, road edges, vehicles, obstacles).
Each of these alone is helpful, but none of them is perfect. That’s why multimodal AI is crucial.
Key Components of Multimodal AI Models
Multimodal
AI models
are built using several core components that work together to interpret multiple data types - such as text, images, audio, and sensor signals - and turn them into
smart, context-aware decisions
. The three fundamental components are:
Encoders
Different types of data require different processing techniques. Encoders take raw inputs and convert them into
vector embeddings
- numerical representations that capture patterns, meaning, and relationships.
How Encoders Work for Each Modality
ModalityEncoder TypeWhat It ExtractsTextNLP Transformers (e.g., BERT)Semantics, context, sentimentImagesCNNs, Vision TransformersObjects, shapes, scenesAudioSpectrogram + RNN/Transformer modelsTone, speech, emotion, keywordsSensor DataTime-Series Models (LSTM, TCN)Movement trends, anomaliesVideoSpatiotemporal ModelsActions, motions, transitions
Encoders ensure
all types of data become machine-readable
, enabling comparison and collaboration across modalities.
Example:
A photo + text description → converted into embeddings that express the
same concept
numerically.
Fusion Layer
Once each modality is encoded, the next step is
fusion
: integrating the embeddings into one
shared multimodal representation
.
Fusion is where real multimodal intelligence is formed.
Common Fusion Strategies
Fusion TypeDescriptionBest ForEarly FusionCombine embeddings before processingTasks requiring deep interaction (e.g., visual question answering)Late FusionSeparate processing, merge final outputsSafety-critical tasks (e.g., self-driving override signals)Hybrid FusionMulti-stage combinationMost enterprise-grade applications
Fusion layers use:
Cross-attention
to align information across modalities
Co-learning
to connect concepts like text = “cat” & image contains cat
Graph fusion
to represent complex relationships
Fusion eliminates data silos inside models, creating
context-aware
,
high-accuracy
intelligence.
Example:
Voice tone (angry) + text (refund demand) → AI understands
customer frustration
accurately.
Decoders
After the multimodal understanding is created, AI must turn intelligence into
actionable results
.
Decoders generate the final output based on the fused representation, such as:
- Text or voice responses
- Recommendations or decisions
- Predictions and forecasts
- Autonomous control actions
Decoders help enterprises implement
automation, prediction, and optimized workflows
.
Supporting Technologies Behind Multimodal AI
To make encoders, fusion layers, and decoders perform at high levels, multimodal systems use:
Core AI Engineering Techniques
Machine learning
- Deep learning neural networks
- Reinforcement learning (for autonomous behavior)
Applied AI Capabilities
- Natural Language Processing (NLP)
Computer Vision (CV)
- Speech recognition and audio analytics
- Sensor data intelligence and robotics
These technologies enable AI to:
- See
- Hear
- Read
- Reason
- Act
…just like a human - but faster, scalable, and data-driven.
Multimodal vs. Unimodal AI: Key Differences
FeatureUnimodal AIMultimodal AIInput TypesSingleMultiple combinedContext AwarenessLimitedHighly accurateInteraction QualityBasicHuman-likeReal-World ScalabilityLowEnterprise-ready
Multimodal AI delivers better intelligence, better automation, and better business outcomes.
Industry Applications of Multimodal AI
Healthcare
- X-rays + medical history → accurate diagnostic support
- Audio + biometrics → smart patient monitoring
Retail & Ecommerce
- Image search + text reviews → personalized recommendations
Banking & Finance
- Face recognition + ID verification → fraud prevention
- Behavioral + transactional data → risk scoring
Manufacturing
- Video + IoT sensor analytics → preventive maintenance
Transportation
- Autonomous driving powered by multimodal perception systems
Media & Marketing
- Video content tagging
- Multimodal AI content creation for branding
Education
- AI tutors detecting gestures + voice → adaptive learning experiences
Multimodal AI is enabling industry-specificAI solutionswith measurable ROI.
Benefits of Multimodal AI for Businesses
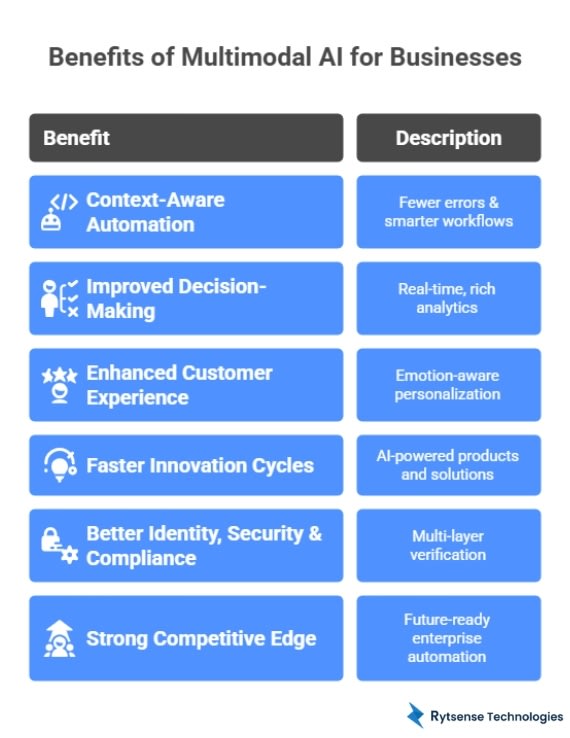
Multimodal AI delivers next-level intelligence by combining multiple forms of data such as images, audio, text, and sensor signals - to produce deeper insights and smarter automation. As a result, businesses unlock measurable improvements in operations, decision-making, and customer experience.
Here’s a detailed breakdown of how multimodal AI transforms enterprises:
Context-Aware Automation → Fewer Errors & Smarter Workflows
Traditional AI automates tasks based on only one input, often missing context. Multimodal AI understands the full situation, enabling:
- Accurate document processing using text + layout + signatures
- Smart quality control using video + sensor analytics
- Intelligent chatbots analyzing voice tone + message content
This eliminates guesswork, reduces agent workload, and improves reliability.
Example:
A customer support bot reads text + detects frustration in voice → escalates to a human agent automatically.
Improved Decision-Making → Real-Time, Rich Analytics
With multiple data sources fused together, decisions come from complete information, not partial signals.
- Banking: ID verification + behavioral analytics → Fraud prevention
- Manufacturing: Machine video + IoT performance signals → Predictive maintenance
- Healthcare: Imaging + EHR data → Faster diagnosis recommendations
Business leaders gain data-driven confidence and faster operational responsiveness.
Enhanced Customer Experience → Emotion-Aware Personalization
Multimodal AI enables businesses to interpret customer intent more accurately:
- Voice + language for sentiment detection
- Body posture + engagement for learning platforms
- Visual search from smartphone camera uploads
Customer feels understood → loyalty, satisfaction, conversions increase.
Retail Example:
Customer uploads a product photo → AI finds similar products + reads the review sentiment → offers the best match.
Faster Innovation Cycles → AI-Powered Products and Solutions
Multimodal capabilities enable new business models and disruptive applications:
- Virtual try-on apps using camera + product metadata
- Smart assistants that see + listen + act
- Robotics combining vision + tactile sensing
Organizations move from digital transformation to AI-driven innovation leadership.
Better Identity, Security & Compliance → Multi-Layer Verification
By combining visual, textual, and behavioral signals, enterprises can strengthen risk and compliance operations:
- Biometrics + ID document validation
- User behavior + location + device identity
- Check fraud with handwriting + signature + document layout
Trust, safety, and compliance become proactive, not reactive.
Particularly impactful in:
- BFSI (Banking, Financial Services & Insurance)
- Government services
- E-commerce & digital identity platforms
Strong Competitive Edge → Future-Ready Enterprise Automation
Companies adopting multimodal AI early:
- Reduce operational costs faster
- Launch smarter products before competitors
- Deliver superior customer interactions
- Make better strategic decisions
Early adopters benefit from long-term ROI and market leadership.
Why Enterprises Are Hiring AI Developers Today
Multimodal AI requires expertise in:
- NLP + computer vision integration
- Data fusion architecture
- Cross-modal model training
- Real-time deployment
That’s why leading companies are partnering with skilled AI developers and AI development service providers to:
- Build scalable multimodal platforms
- Customize models for business-specific requirements
- Modernize workflows with automation
- Maintain accuracy, performance, and compliance
Investment in multimodal AI talent = Faster, safer, more successful transformation.
Business AdvantageResultContext-aware automationFewer errors and smarter workflowsImproved decision-makingRich analytics and real-time intelligenceEnhanced customer experienceEmotion-aware personalizationFaster innovation cyclesNew product capabilitiesBetter identity and compliance controlMulti-layer verificationStronger competitive edgeFuture-ready automation
This is why leading organizations are increasingly hiring AI developers to accelerate their transformation roadmap.
Challenges in Multimodal AI Implementation
Even with incredible benefits, enterprises face challenges like:
- Data complexity and standardization issues
- Large computational requirements
Data privacy and governance concerns
- Lack of multimodal benchmarking standards
- Skill gaps in AI model development and deployment
Partnering with the right AI development company helps overcome these barriers efficiently.
Future Trends: Toward Agentic Intelligence
Multimodal AI is the gateway to agentic AI - where systems:
- Perceive the world like humans
- Reason across multiple data streams
- Take autonomous actions
- Continuously learn from outcomes
- Collaborate like intelligent coworkers
Upcoming innovations include:
- Universal AI assistants
- Multilingual multimodal copilots
- Smart robotics with multisensory intelligence
- Enterprise AIsystems executing business processes autonomously
This is the foundation of the next generation of AI-driven digital transformation.
How to Implement Multimodal AI in Your Organization
Successfully integrating multimodal AI into the enterprise requires a strategic and structured approach. By combining the right use cases, robust data foundations, advanced AI technologies, and expert talent, businesses can accelerate transformation and unlock new revenue opportunities.
Select High-Value Use Cases
Start by prioritizing areas where multimodal intelligence adds measurable impact. Consider use cases where multiple data types - text, images, audio, sensor data - drive better accuracy and decision-making:
- Customer Support Automation
AI agents that understand voice, text, and sentiment to deliver faster, more personalized support. - Fraud & Risk Detection
Multimodal anomaly detection using transactional data, identities, and behavioral patterns in real time. - Product Discovery Engines
Unified search and recommendation systems powered by text descriptions, visuals, and user behavior. - Operational Monitoring
Industrial IoT insights combining camera feeds, logs, and sensor signals for predictive maintenance and safety.
These high-ROI applications help organizations prove value early while scaling gradually.
Prepare Your Data Infrastructure
Multimodal AI succeeds only with clean, connected, and governed data. Key readiness steps include:
- Data Integration
Unify structured and unstructured inputs — databases, media files, documents, etc. - Security and Compliance
Enforce access control, ensure regulatory compliance, and protect sensitive data. - Model Training Readiness
Establish pipelines for labeling, preprocessing, and real-time data streaming to enable continuous learning.
A strong foundation reduces deployment friction and improves model performance at scale.
Select the Right AI Technologies
Choose technology that aligns with your scalability, regulatory, and operational requirements:
- Cloud-Based AI Platforms
Leverage scalable compute, pre-trained models, and powerful developer tools. - APIs for Vision, NLP & Speech
Faster go-to-market with prebuilt capabilities integrated into existing systems. - Custom AI Model Development
Tailored intelligence for domain-specific tasks and competitive differentiation.
Hybrid architectures enable optimal cost-efficiency and speed.
Onboard Experienced AI Developers
Expert guidance ensures multimodal AI is deployed responsibly and effectively:
- End-to-End Development
From planning and prototyping to integration and continuous improvement. - Real-Time Deployment
Edge, cloud, and hybrid delivery for mission-critical use cases. - Performance Optimization
Improve speed, latency, scalability, and model accuracy over time. - Ethical AI Adoption
Built-in fairness, transparency, and human oversight. - Scalable Execution
Roadmaps that allow for organization-wide expansion without disruption.
Investing in the right skills drives long-term success and competitive advantage.
Conclusion
The multimodal approach in AI is reshaping how machines understand and interact with the world. By combining diverse data like images, text, audio, and sensor inputs, multimodal AI unlocks more accurate intelligence, proactive automation, and deeper business insights.
For startups and enterprises, this represents a major leap forward in innovation - enabling smarter products, efficient decision-making, and a stronger competitive position in the AI-driven economy. Organizations that embrace multimodal AI now will be the industry leaders of tomorrow.
Meet the Author

Co-Founder, Rytsense Technologies
Karthik is the Co-Founder of Rytsense Technologies, where he leads cutting-edge projects at the intersection of Data Science and Generative AI. With nearly a decade of hands-on experience in data-driven innovation, he has helped businesses unlock value from complex data through advanced analytics, machine learning, and AI-powered solutions. Currently, his focus is on building next-generation Generative AI applications that are reshaping the way enterprises operate and scale. When not architecting AI systems, Karthik explores the evolving future of technology, where creativity meets intelligence.