Key Takeaways
LLMs (Large Language Models) understand and generate text only, making them ideal for writing, summarization, chatbots, and text-based automation.Multimodal AI can process text, images, audio, video, code, and documents, giving it a human-like ability to perceive and understand real-world data.LLMs read, while multimodal AI perceives—making multimodal systems more suitable for industries that rely on visuals, voice, or multi-format data.LLMs are simpler and more affordable, making them perfect for startups and text-heavy workflows.Multimodal AI is more powerful and adaptable, enabling advanced use cases like defect detection, medical imaging, document intelligence, and multimodal copilots.Businesses in 2025 prefer multimodal AI because their data sources (PDFs, images, calls, videos) require a multi-sensory AI approach.Choosing LLM vs multimodal AI depends on your needs—text-focused tasks use LLMs; real-world automation uses multimodal AI.AI development services help companies build, integrate, and deploy these systems, ensuring accuracy, scalability, and compliance.Future AI trends move from LLM → Multimodal → Autonomous AI, enabling intelligent agents that can perceive, reason, and act.Partnering with a Top AI Development Company is essential to build reliable, enterprise-ready AI solutions.
What Is the Difference Between LLM and Multimodal AI?
The key difference is simple:
- An LLM (Large Language Model) understands and generates text only.
- Multimodal AI understands and generates multiple types of data—text, images, audio, video, code, and more.
LLMs process language. Multimodal AI processes language + visuals + sound + other inputs together.
This is why multimodal AI — now widely used across industries through AI development services — is more capable for real-world tasks like analyzing images, reading documents, interpreting charts, processing voice, and generating multimedia outputs.
1. What Is an LLM?
An LLM (Large Language Model) is an AI system trained to understand, generate, and reason about text. LLMs like GPT-3.5, GPT-4, Claude 2, and Llama 3 can:
- Answer questions
- Write content
- Analyze documents
- Generate code
- Summarize text
- Perform reasoning
LLMs are powerful, but they are single-modality models, meaning they only work with language.

Why LLMs Became Popular
LLMs transformed AI because they made natural language interaction possible. Companies use LLMs for:
- Chatbots
- Content automation
- Coding assistance
- Knowledge management
- Customer support
- Document summarization
However, LLMs cannot “see” images, “hear” audio, or interpret multimodal signals—unless extended with additional AI models or multimodal encoders.
2. What Is Multimodal AI?
Multimodal AI is an advanced form of artificial intelligence capable of understanding, processing, and generating multiple types of data simultaneously. Unlike traditional LLMs that work only with text, multimodal AI models can interpret information from different modalities—much like humans do.
Types of Data Multimodal AI Can Understand
A multimodal AI model can work with:
- Text – reading instructions, documents, conversations
- Images – analyzing photos, diagrams, UI screens, medical scans
- Audio – understanding speech, tone, voice patterns
- Video – interpreting movement, scenes, activities
- Code – reading, debugging, generating application logic
- Sensor data – IoT signals, time-series data, industrial metrics
- Documents – PDFs, receipts, invoices, scanned forms
- Charts & Graphs – extracting insights from dashboards and visuals
This ability to combine different formats makes multimodal AI one of the most impactful advancements in machine learning, deep learning, and generative AI.
Popular Multimodal AI Models
Examples include:
- OpenAI GPT-4o & GPT-4 Vision
- Google Gemini 1.5
- Meta LLaVA-based models
- Microsoft Copilot (Vision + Text + Code)
- OpenAI Sora (Video generation)
What Multimodal AI Can Do
Compared to LLMs, multimodal AI can:
- Analyze product images
- Understand charts, graphs, dashboards
- Read invoices or receipts
- Detect defects in manufacturing
- Process voice conversations
- Generate images or video from text
- Interpret screenshots and write code
- Combine audio + visual + text inputs
Multimodal AI sits at the center of generative AI, machine learning, deep learning, and modern enterprise automation.
3. Key Differences Between LLM and Multimodal AI
To understand why businesses are rapidly shifting toward multimodal AI, it helps to compare it directly with traditional LLMs. Below is a detailed explanation of each comparison point.

1. Input TypeLLM: Accepts only text. Processes sentences, paragraphs, documents, and code. Vision analysis requires external models.Multimodal AI: Accepts multiple inputs (Text, Images, Audio, Video, Code, Documents, Sensors). Far more flexible for real-world data.2. Output TypeLLM: Limited to text generation (Answers, Summaries, Code snippets). Cannot natively produce images or audio.Multimodal AI: Generates multiple formats (Text, Images, Audio, Video summaries, Code from screenshots). Richer, multi-sensory experiences.3. Understanding AbilityLLM:Language only. Reasoning is confined to linguistic relationships and word patterns.Multimodal AI:Multi-sensory understanding. Recognizes spatial relationships, detects audio cues, and combines multiple signals for human-like reasoning.4. Use CasesLLM: Best for text-heavy workflows (Chatbots, Summarization, Email automation, Policy assistants).Multimodal AI: Best for real-world automation (Vision AI for defects, Speech AI for voice auth, Intelligent Document Processing, Video analytics).5. ComplexityLLM: Lower complexity, faster to train/deploy. Ideal for startups building text-driven apps.Multimodal AI: Higher complexity. Requires multiple encoders, specialized datasets, and high compute power. Usually built by specialized AI development companies.6. Real-World AdaptationLLM: Limited as the world is not text-only. Struggles with mixed-input workflows (screenshots, voice data).Multimodal AI: Highly practical. Solve real-world problems in Manufacturing (image detection), Healthcare (scans), and Finance (PDF/Chart analysis).7. Best ForLLM: Text-heavy tasks, content generation, coding assistants.Multimodal AI: Multi-format enterprise workflows, technical inspection, and complex automation involving visuals + text + audio.
Feature Summary
FeatureLLMMultimodal AIInput TypeText onlyText, images, audio, video, codeOutput TypeTextText + images + audio + videoUnderstandingLanguageMulti-sensoryUse CasesChatbots, writing, text analysisVision, speech, video, automationComplexityLowerHigherReal-World AdaptationLimitedHighly practicalBest ForText-heavy tasksMulti-format business tasks
Summary: LLMs read. Multimodal AI perceives.
4. Why Multimodal AI Matters More in 2025
The world is not text-only. Businesses work with diverse data formats every day, including:
- Images
- PDFs
- Voice calls
- Screenshots
- Videos
- Sensor data
- Dashboards
Multimodal AI can interpret all these formats — something LLMs cannot do alone. This expands AI capabilities dramatically.
Key Benefits for Businesses:
- Better Accuracy: Combining signals (e.g., text from a call + sentiment from audio).
- Faster Decisions: Automated analysis of visual evidence and reports.
- End-to-End Workflow Automation: Processing a document from scan to database.
- Human-Like Understanding: AI that perceives the environment as we do.
- Richer Insights: Extracting patterns from hidden data in videos or IoT sensors.
This is why companies are shifting from LLM-only tools to custom AI development services that support multimodal intelligence.
5. How Businesses Use LLMs vs Multimodal AI
LLM Use Cases (Text-Only)LLMs excel at linguistic tasks: Document summarization Chatbots and assistants Email automation Knowledge extraction Coding help Policy/Q&A systemsCost-effective, fast, and easy to deploy.Multimodal AI Use CasesPowers complex, multi-format workflows:Healthcare: X-ray + text analysisE-commerce: Image-based searchManufacturing: Defect detectionFinance: Document + visual extractionDevOps: Screenshot → code generationReal Estate: Visual property valuation
Summary
LLMs are good for text. Multimodal AI is good for real-world complexity.
6. When Should You Use LLMs?
Choose an LLM when:
- Your workflow is text-focused.
- You want fast, low-cost automation.
- You need writing, summarization, or Q&A features.
- You’re building a simple chatbot or internal knowledge assistant.
Startups often begin with LLMs because they are simple to deploy and manage.
7. When Should You Use Multimodal AI?
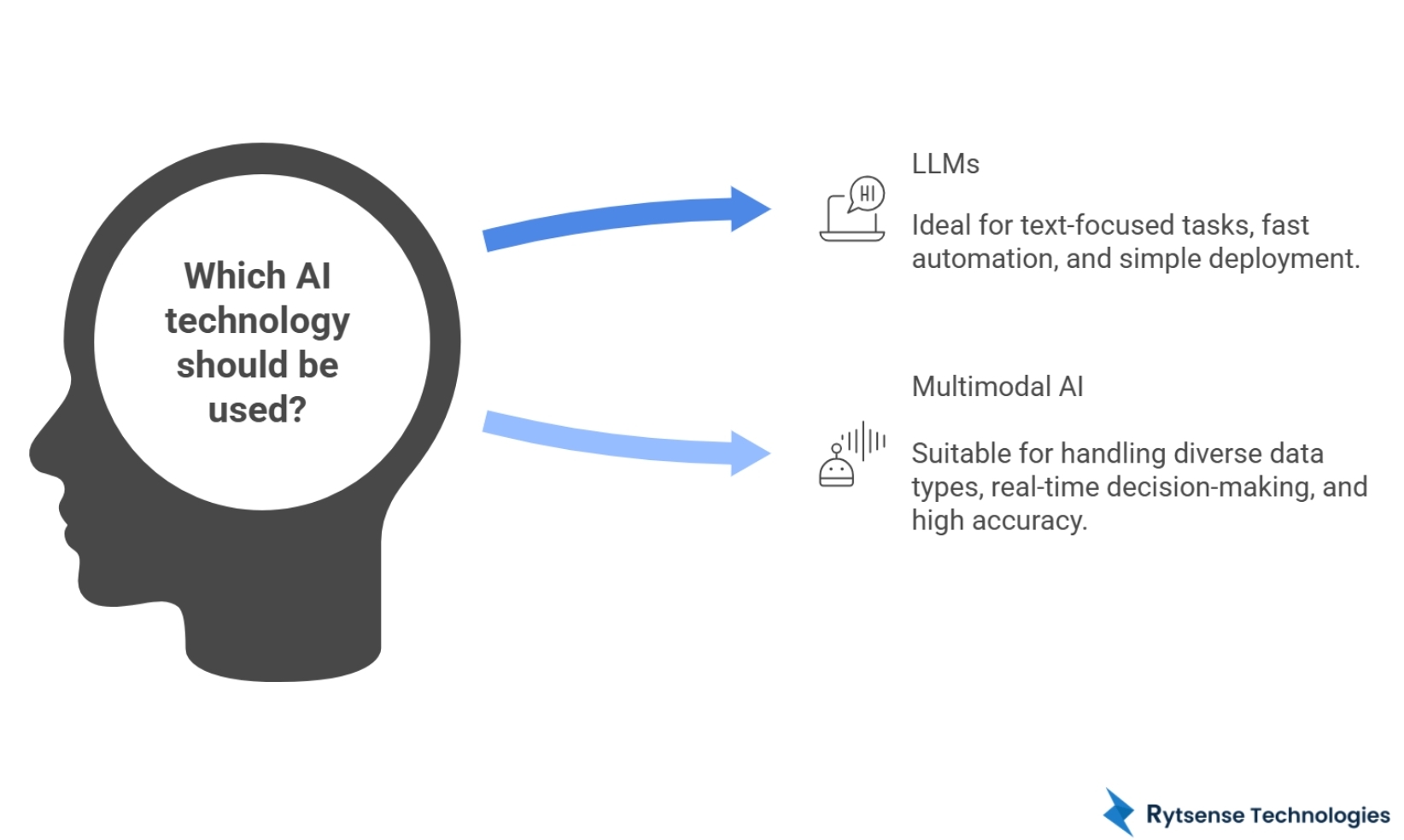
Choose multimodal AI when:
- You deal with images, PDFs, or screenshots.
- You need audio transcription or sentiment analysis.
- You want AI to interpret charts, graphs, or dashboards.
- You want real-time decision-making from visual inputs.
- Your product requires high accuracy from diverse data sources.
- You are building complex automation systems (e.g., MLOps).
Enterprises use multimodal AI to replace manual inspection, reading, scanning, and operations—especially with the help of AI developers who specialize in vision and speech models.
8. Technical Architecture Differences
LLM Architecture Transformer-based model Trained on text corpora Single input channel (text) Predicts next word/tokenMultimodal AI Architecture Multiple encoders (vision, audio, text) Joint embedding or fusion layers Cross-attention mechanisms Multi-output generation Trained on diverse datasets
In short: LLMs = simple, linear, text-focused | Multimodal AI = complex, integrated, multi-layered
9. Challenges in Building Multimodal AI
Even though multimodal models are powerful, companies face these hurdles:
- High training and compute costs: Processing video and images requires massive GPU power.
- Need for specialized datasets: Gathering diverse, high-quality paired data (e.g., medical scans with expert notes).
- Integration with legacy systems: Modernizing older enterprise architectures to support multi-signal inputs.
- Real-time performance requirements: Ensuring low-latency responses for voice or video analysis.
- Data privacy and compliance: Handling sensitive visual and auditory data securely.
Because of this, companies work with professional AI development services that offer enterprise-grade integration, security, and scalability.
10. The Role of AI Development Services
An experienced AI development company helps businesses navigate the complex landscape of artificial intelligence:
- Choose between LLM and multimodal AI based on ROI.
- Build custom AI applications tailored to industry needs.
- Fine-tune models for specific domain expertise.
- Integrate AI seamlessly into existing software ecosystems.
- Deploy models on cloud (AWS, Azure, GCP) or on-premise.
- Ensure accuracy, security, and regulatory compliance.
This is crucial for startups and enterprises aiming to modernize their products with AI development services, machine learning, and generative AI capabilities.
11. Future Trends: LLM → Multimodal → Autonomous AI
AI evolution is happening at a breakneck pace:
Phase 1: LLMsText-only intelligence (Reading and writing).Phase 2: Multimodal AI (Today)Text + Image + Audio + Video (Perceiving and understanding).Phase 3: Autonomous AI (Next)AI agents that can take actions, make decisions, execute tasks, and operate independently within workflows.
Multimodal AI is the foundation of this future.
12. Conclusion
The difference between LLM and multimodal AI is clear: LLMs understand text. Multimodal AI understands text, images, audio, video, and more.
LLMs transformed communication. Multimodal AI is transforming the entire digital economy, enabling high-level reasoning and perception across industries. Startups use it to innovate faster; enterprises use it to automate smarter.
Understanding these differences helps businesses choose the right AI technology and build scalable, future-ready solutions. Partnering with a Top AI Development Company like Rytsense Technologies ensures you stay ahead in the 2025 AI race.
Meet the Author

Co-Founder, Rytsense Technologies
Karthik is the Co-Founder of Rytsense Technologies, where he leads cutting-edge projects at the intersection of Data Science and Generative AI. With nearly a decade of hands-on experience in data-driven innovation, he has helped businesses unlock value from complex data through advanced analytics, machine learning, and AI-powered solutions. Currently, his focus is on building next-generation Generative AI applications that are reshaping the way enterprises operate and scale. When not architecting AI systems, Karthik explores the evolving future of technology, where creativity meets intelligence.