Key Takeaways
Multimodal AI differs from traditional AI by processing multiple inputs (text, visuals, audio, sensors) together, whereas most earlier AI models rely on a single data type, limiting accuracy and real-world understanding.
Because it learns from cross-modal data, multimodal AI delivers context-aware predictions, human-like reasoning, and richer personalization — ideal for applications that need visual, verbal, and behavioral intelligence.
Businesses leveraging multimodal AI can unlock smarter automation, fraud detection, product discovery, medical analytics, and more — driving measurable ROI and giving a strong competitive edge.
While complexity, infrastructure, and talent requirements are challenges, partnering with expert AI development teams accelerates adoption and reduces risk.
For startups and enterprises focused on innovation, multimodal AI is the next major leap in AI-driven digital transformation, enabling scalable intelligence for future-ready products and services.
How Is Multimodal AI Different From Other AI? A Complete Guide for Businesses & Innovators (2025)
Artificial intelligence is evolving at a rapid pace. From chatbots to self-driving cars, every innovation relies on models that can understand the world around them. But until recently, most AI systems relied on only one form of input - text, images, or audio alone.
Today, multimodal AI is transforming what’s possible.
It allows systems to see, hear, read, speak, and interpret multiple data types together, creating richer intelligence than traditional artificial intelligence models. As organizations adopt advanced AI development services, multimodal AI is becoming the key differentiator for real-world success - from predictive analytics in finance to personalized product recommendations in eCommerce.
This blog explains how multimodal AI differs from other AI, where it can be used, and why startups and enterprises should start exploring custom AI development to stay competitive.
What Is Multimodal AI?
A multimodal approach in AI refers to systems that process and interpret multiple types of data at the same time - such as:
- Text (language)
- Images & videos (vision)
- Audio (speech)
- Sensor data
- Structured business data
This mirrors how humans understand the world, through a combination of senses.
Example: A multimodal AI model can watch a video, understand the dialogue, identify objects in the scene, and describe what is happening, in real time.
This is different from:
- A chatbot that only understands text
- A vision model that only analyzes images
Multimodal AI = Better context and meaningful decision-making

If you're exploring AI software development or innovative use cases for your business, our experts can guide you with a quick consultation.
Types of AI Inputs: Unimodal vs Multimodal Systems
To understand how multimodal AI stands out, let’s compare:
| Feature | Unimodal AI Models | Multimodal AI Models |
|---|---|---|
| Input type | One data modality (text OR image OR speech) | Multiple modalities simultaneously |
| Context understanding | Limited & narrow | Deep, contextual & human-like |
| Output | Basic predictions | Multi-layer intelligence |
| Real-world adaptability | Moderate | Highly adaptive |
| Example | OCR tools, text classifiers, speech assistants | GPT-4o, Gemini, Copilot, autonomous vehicles |
Traditional models are strong in single tasks, but they lack broader perception.
Our AI developers for hire can help build and deploy real multimodal systems tailored to your workflows.
How Multimodal AI Works (Simple Overview)
Behind the scenes, multimodal intelligence uses:
- Neural networks to process data formats
- Deep learning models to combine features
- Fusion techniques to merge understanding into one output
- Machine learning pipelines for decision-making
A Quick Example Flow:
Image + Audio + Text → ML Model → Unified Interpretation → Action
This enables capabilities like:
- Reading a product label
- Understanding spoken instructions
- Detecting product defects visually
- Taking action autonomously
It’s a foundation for future AI app development, including robotics, healthcare imaging, and autonomous tech.
Multimodal AI vs. Other AI Models: Key Differences
To really understand how multimodal AI stands apart from other AI models, it helps to look at four core areas: how it understands information, how it learns, how it interacts with users, and where it performs best in the real world.
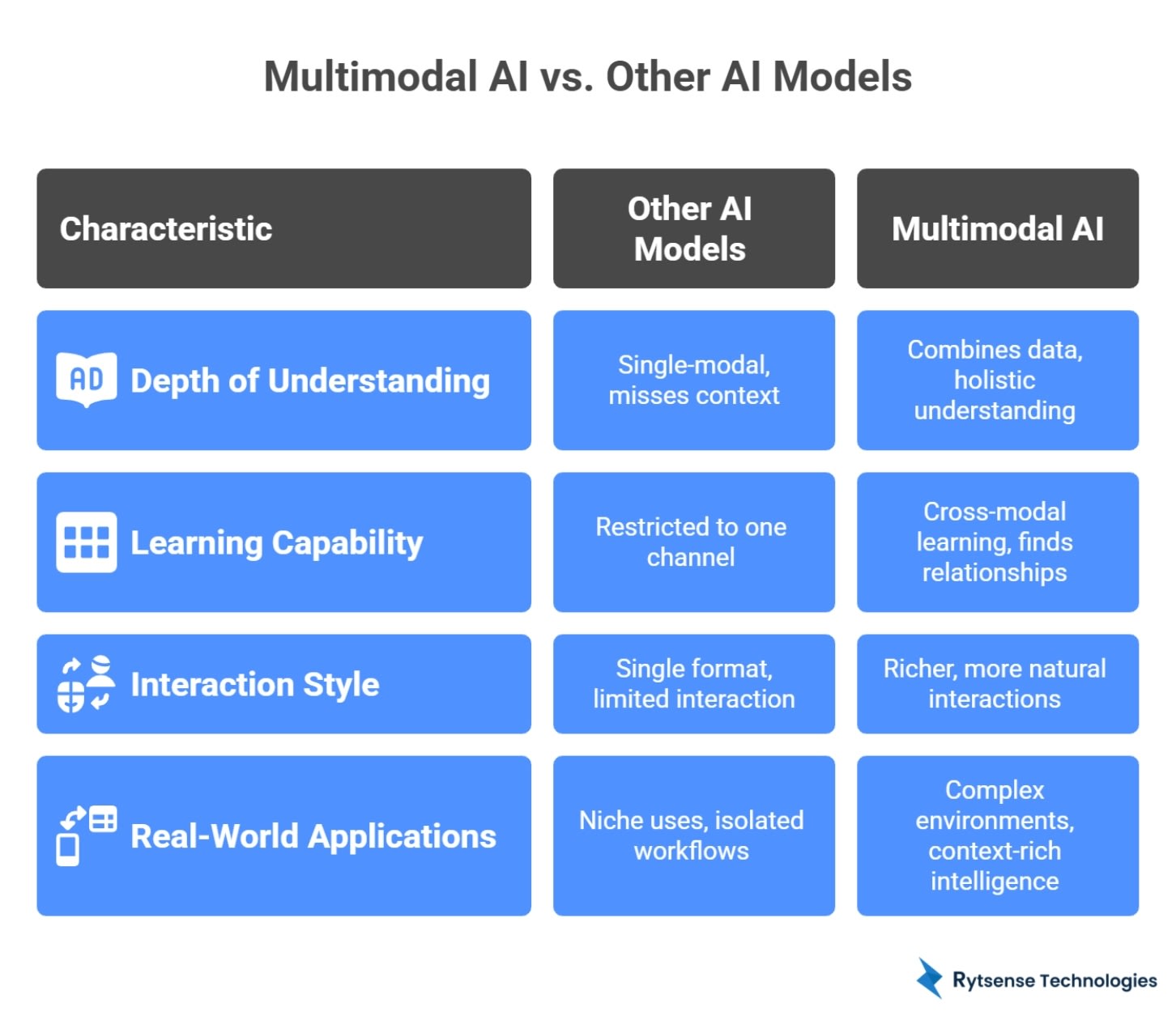
Difference #1 - Depth of Understanding
Other AI models: Most traditional AI systems are single-modal, meaning they work with just one type of input at a time — for example:
- A text-only chatbot
- An image recognition system
- A speech-to-text transcription tool
Because each of these models only “sees” one slice of reality, they often miss context. A text model can read a sentence but can’t see facial expressions. A vision model can detect objects but can’t understand the spoken conversation happening in the scene.
Multimodal AI:
Multimodal AI is designed to combine different types of data at once, such as:
- Text + images
- Video + audio
- Sensor readings + structured business data
By blending these signals, multimodal models don’t just classify or label; they understand the situation more holistically.
Example:
Imagine a customer support system that:
- Listens to a customer’s tone of voice,
- Analyzes their facial expressions on video,and
- Reads the chat transcript or previous emails.
A traditional text-only chatbot might respond politely but miss the customer’s frustration. A multimodal AI system can detect both the words and the emotion, then prioritize the case or route it to a human agent with the right context. That’s a deeper level of understanding that other AI models don’t naturally have.
Difference #2 - Learning Capability
Other AI models:
Single-modal AI learns patterns from one type of input. For instance:
- An NLP model learns patterns from large text datasets
- A vision model learns visual features from image datasets
These models can be powerful in their domain, but learning is restricted to one channel. They cannot leverage information from other modes to strengthen their understanding.
Multimodal AI:
Multimodal AI learns through cross-modal learning, which means it finds relationships across different types of data.
When a model sees an image, reads associated text, and maybe hears linked audio, it can:
- Align visual features with language (e.g., “stethoscope” ↔ image of a doctor using it)
- Understand how speech relates to actions in a video
- Connect numerical data (like vitals or metrics) with real-world visual cues
This cross-modal learning improves its predictions and generalization.
Example: Medical Use Case
Consider a multimodal model used in healthcare:
- It looks at medical scans (like X-rays or MRIs),
- Reads patient health records, and
- Takes into account structured data such as lab test results.
Instead of relying on the scan alone, the model learns complex relationships between visual patterns and clinical history. This can lead to more precise diagnosis suggestions, better risk scoring, and earlier detection of anomalies than a single-modal model analyzing just one data source.
Difference #3 - Interaction Style
Other AI models: Most traditional AI systems interact in only one format:
- A chatbot replies in text
- A voice assistant responds through speech
- A vision model outputs labels or bounding boxes
This interaction style is useful but limited. It forces users to adapt to the machine’s preferred mode rather than the other way around.
Multimodal AI:
Multimodal AI supports richer, more natural interactions because it can:
- Understand voice commands
- Read text input
- Analyze images, gestures, or video feeds
- Render responses as text, speech, visuals, or even AR/VR overlays
This makes AI systems feel more human-centric and intuitive.
Example: Immersive User Experience
Think of an AR shopping assistant that:
- Listens to what the user says (“Show me sofas that match this wall color”),
- Analyzes a photo of the room,
- Understands gesture inputs (like pointing to a corner), and
- Overlays 3D models of furniture in the space.
A single-modal AI can’t deliver this level of experience. A multimodal AI model can interpret voice, visuals, and context together, making the interaction seamless and engaging.
Difference #4 - Real-World Applications
Other AI models: Traditional AI is often built for niche uses:
- OCR tools for text extraction
- Vision models for defect detection in factories
- Chatbots for basic customer queries
They solve specific problems but operate in isolated workflows.
Multimodal AI:
Multimodal AI, on the other hand, is naturally suited for complex, real-world environments where multiple inputs are always present. It’s especially powerful in industries like:
- Automotive – Autonomous vehicles using cameras, LiDAR, GPS, and traffic data.
- Retail & eCommerce – Visual search mixed with text queries and behavioral data for product recommendations.
- Manufacturing – Cameras + vibration sensors + sound analysis for predictive maintenance and quality control.
- Banking & Finance – Fraud detection using transaction patterns, device data, location, and biometric verification.
- Media & Entertainment – AI that analyzes video, audio, and viewer reactions to personalize content.
- Healthcare & Biotech – Medical imaging combined with clinical notes and lab results for diagnosis support.
In these cases, relying on just one data type isn’t enough. Business decisions and safety-critical systems require context-rich intelligence, and that’s where multimodal AI shines.
It effectively bridges the gap between AI theory and AI practicality - moving from “smart algorithms” to truly intelligent systems that understand real-world situations the way humans do.
Build AI With a Competitive Edge
Upgrade from simple automation to true intelligence.
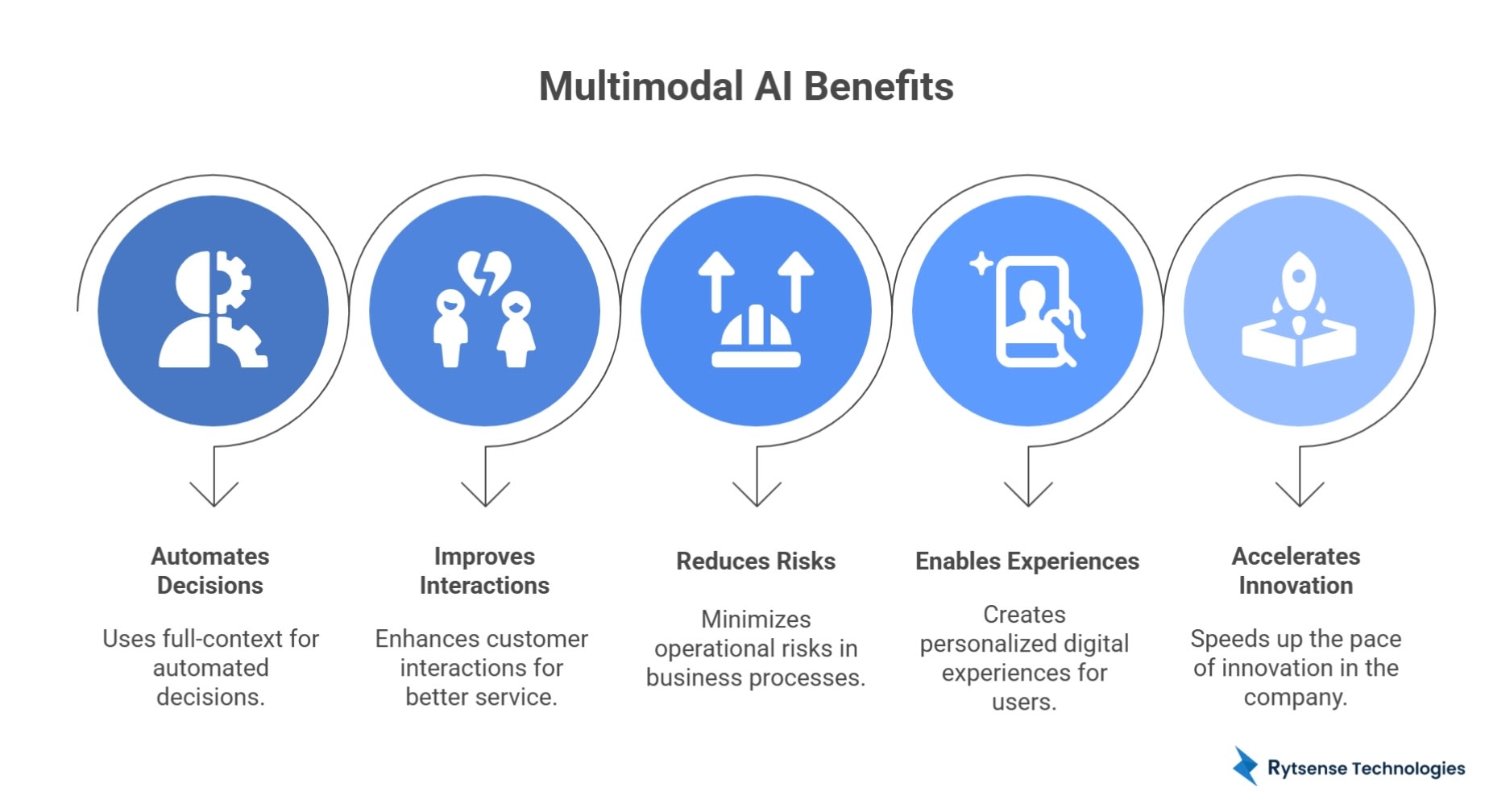
Why Multimodal AI Matters for Businesses & Startups
- Automates decisions using full-context
- Improves customer interactions
- Reduces operational risks
- Enables personalized digital experiences
- Accelerates innovation
Top Business Benefits
| Benefit | Result |
|---|---|
| Context-aware workflows | Higher precision, fewer errors |
| Real-time intelligence | Faster & better decision-making |
| Emotion & behavior recognition (NLP + vision) | Personalized products and support |
| Multi-layer verification | Better identity & compliance handling |
| Competitive advantage | Innovation at reduced cost |
Companies adopting multimodal AI development services are gaining measurable ROI through smarter automation.
Powerful Real-World Use Cases Across Industries
| Industry | Multimodal Use Case |
|---|---|
| Retail & eCommerce | Personalized product discovery using image + text search |
| Healthcare | MRI scans and medical records → accurate diagnosis system |
| Banking | Fraud detection with behavioral + biometric signals |
| Travel & Hospitality | AI agents that understand speech + visual identity verification |
| Education | Interactive learning with voice + handwriting recognition |
| Automotive | Autonomous driving with video + sensor fusion |
| Manufacturing | Quality inspection combining camera + audio anomaly detection |
These applications are already shaping the standards of digital transformation.
Technologies Powering Multimodal AI
Key AI technologies used in multimodal model development:
- Natural Language Processing (NLP)
- Computer Vision
- Speech Recognition
- Sensor Fusion
- Neural Networks & Deep Learning
- Large Language Models (LLMs)
- Custom AI solutions & APIs
Popular multimodal tech examples include:
- GPT-4o
- Google Gemini
- Amazon Q
- Meta’s Vision-Language Models
These models combine foundational AI models into one intelligence system - amplifying efficiency and creativity.
Challenges in Implementing Multimodal AI
Even powerful systems bring complexities:
| Challenge | Explanation |
|---|---|
| Data collection at scale | Requires labeled multimodal datasets |
| High-performance infrastructure | GPUs, cloud-based AI platforms |
| Ethical + security concerns | Data privacy & responsible deployment |
| Integration with existing systems | Needs expert AI software development |
| Skilled talent requirement | Experienced AI developers needed |
Forward-thinking enterprises are partnering with AI development companies to overcome these roadblocks with custom solutions.
From model training to deployment - we handle it end to end.
How to Get Started With Multimodal AI Development
Here’s a clear roadmap for organizations:
- Identify high-value use cases
- Start with a POC (proof of concept)
- Prepare structured & unstructured data
- Select cloud-based AI technologies
- Hire expert AI developers
- Integrate into business workflows
- Scale and optimize with new features
Whether enhancing existing systems or launching new AI projects, starting small ensures faster results and reduced risk.
Future of Multimodal AI: What’s Next?
- AI agents with independent decision-making
- Full-scale automation across industries
- Augmented reality & wearable AI integration
- Human-like conversation experiences
- Smarter robotics for industrial operations
- More accessible AI app development for SMEs
The future belongs to multimodal intelligence.
Organizations that adopt now will lead innovation across global markets.
Conclusion: Why Multimodal AI Is the Next Big Leap in AI
Most traditional AI systems operate with limited perception. But businesses now demand AI that:
- Understands real-world context
- Interacts naturally
- Improves decision-making
- Enhances customer value
That’s where multimodal AI stands out. Startups and enterprises investing in custom AI development today will dramatically improve productivity, customer experience, and growth opportunities tomorrow.
Transform Your Business With Multimodal AI
Whether you want to automate processes, build intelligent products, or explore the latest AI technologies:
Meet the Author

Karthikeyan
Connect on LinkedInCo-Founder, Rytsense Technologies
Karthik is the Co-Founder of Rytsense Technologies, where he leads cutting-edge projects at the intersection of Data Science and Generative AI. With nearly a decade of hands-on experience in data-driven innovation, he has helped businesses unlock value from complex data through advanced analytics, machine learning, and AI-powered solutions. Currently, his focus is on building next-generation Generative AI applications that are reshaping the way enterprises operate and scale. When not architecting AI systems, Karthik explores the evolving future of technology, where creativity meets intelligence.